So far we've only discussed having one table in a database. In the merits database, for example, we've talked about using the following fields to store the information about the merits:
- Name
- Tutor group
- Teacher
- Subject
- Date
- Reason
- Head of year
- Tutor
Data Redundancy & Inconsistency
This database structure would do the job, but think about what would happen as you enter the merits. For each new merit you add, you need to enter all of the teacher and student details each time. This would involve a lot of data being duplicated, and therefore take up a lot more disc space. This is known as redundancy.
As well as requiring more space, and time to enter, a number of other problems could arise. If you're having to enter all the details each time, there is a risk that you could make a mistake whilst entering some of the details, leading to, for example, a number of different spellings of a student's name. And what happens if a student changes tutor group half-way through the year, and you want to find the total number of merits for a particular tutor group?
Multiple Tables
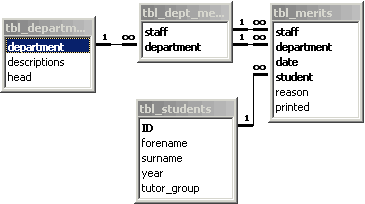
The solution to this problem is to use a database that consists of several tables - a relational database. This involves separating out the various fields into logical units, or entities. Each entity would normally represent one person, or thing. These entities are then linked by a relationship, and the whole database structure can be represented by a thing called an Entity-Relationship Diagram. Access allows you produce an entity-relationship diagram of sorts - an example of one solution to the merits problem is shown on the right.
The logical units, or entities, in the merits system are the students, the staff, and the merits themselves (you can download the merits database as either an .mdb or .accdb file.). This means that the details of the students and the members of staff only need to be entered once. When you enter a new merit, you only need to enter enough information to identify the student and the member of staff (i.e. staff initials & department, and student number) - the remaining information can then be looked up from the staff and student tables. If you're using Access, you can create forms for use with the database so that that user can select from staff and student names, whilst only storing the initials and student number in the merits table.
I have included the extra entity, containing just staff and department, because each member of staff may teach more than one subject. There are also more entities which are not shown in the diagram, such as staff and tutor group (identifying tutor and head of year) tables.
The relationships (i.e. the lines on the diagram) link together the fields in the two tables that contain the same information - e.g. the student field in the tbl_merits table and the ID field in tbl_students both have the same type, and both contain an integer that is unique to each student. This means that there is still a very small amount of duplication (just one extra number per student), but nowhere near as much as there is in the single table solution. A field that is linked to another table is called a foreign key. A foreign key in one table is always linked to a key field in another table (the key fields are shown in bold - more than one bold field indicates a compound key).
Degree of Relationship
You will probably have noticed that the relationships have little symbols at the end, either a 1 or the infinity symbol. These indicate the degree of the relationship, where the infinity symbol means many. The degree indicates the nature of the relationship between the entities - for example, in the merits database shown above, one department can have many members of staff, one member of staff can give many merits, and each student can have many merits give to them. One the other hand, each merit can only be given by one member of staff, and can only be given to one student.
Access doesn't use the standard notation, however. It is more usual to indicate the degree using the line alone - with a single line at the one end, and a three-tined fork at the many end. Obviously, there are three possible types of relationship:
- one-to-one
- one-to-many (or vice-versa)
- many-to-many
although many-to-many relationships are frowned upon in database design, as they introduce ambiguity, and should be removed using Normalisation.
Searching (or Queries)
Another reason to use a relational database is that it makes it much easier to query, or search, certain fields.
Imagine that a library allowed you to borrow up to six books, and had a simple database with the following fields:
- borrower name
- address
- phone number
- book1
- book2
- book3
- book4
- book5
- book6
If you wanted to find out who had borrowed a particular book, e.g. "Databases for Beginners", you would have to have a query like this:
Nice! Now, if you split up your database so that you had three tables, it would be much easier. You'd have tables for books and borrowers, and then one for the actual process of borrowing a book, that would just contain the borrower ID and probably the ISBN number. If the ISBN of the book you were looking for was 0123456789, for example, then you could find out who had borrowed by just searching for:
Much simpler, I'm sure you'll agree!
Referential Integrity
What would happen if you had two records in your database that were linked by a relationship, and then the foreign key or the primary key changed? Or one of the records was deleted from the database? For example, in our merit database, what would happen if you gave a merit to someone who then changed tutor groups or left the school completely?
The two records would no longer be linked properly, and "referential integrity" would be lost (i.e. the rules governing how the data are related have been broken).
There are two ways around this problem:
- The simplest thing would be to stop the user making any change that would threaten referential integrity. You may have already noticed that Access won't let you delete information from a linked field, or enter information that would prevent it from being linked to another table (e.g. in our merit database, it won't let you enter merits for students or staff who don't exist in the student and staff tables).
- Some database programs allow you to "cascade" any changes to keys to other tables, so that if you change a key field, the matching fields in other tables are also changed. So, if one of the students in our student database were to change tutor group, for example, the tutor group field in the merit table would also be updated and the records would still be linked.
Normalisation
The process of organising your database to maximise efficiency and minimise the likelihood of data redundancy is called normalisation.